Structural Vulnerabilities in Agentic Document Processing Pipelines
Types of Attacks on Language Models
As enterprises increasingly integrate Large Language Models (LLMs) into automated workflows, ranging from resume parsing to high-stakes financial auditing, the security paradigms surrounding these systems have required significant recalibration. Modern agentic systems typically leverage language models at multiple stages to orchestrate complex, multi-step tasks. Because these models ultimately produce outputs as a statistical function of their input sequences, the integrity of the ingestion layer is key.
Research into agentic vulnerabilities has demonstrated that current models are often "brittle" when subjected to non-standard inputs. Malicious actors and sophisticated users have developed diverse methods to alter model behavior through input manipulations, some of which can be categorized as follows:
- Direct Prompt Injection: This occurs when a user explicitly provides adversarial instructions to bypass safety alignments or developer-defined system prompts. The goal is typically to generate prohibited content or force the model out of its intended operational boundary.
- Indirect Prompt Injection: As autonomous agents gain the ability to retrieve external documents and utilize APIs, they become susceptible to IPI. In this vector, malicious instructions are concealed within third-party content (e.g., webpages, emails, documents). Recent research notes that agents processing IPIs often exhibit abnormally high internal decision entropy, indicating a latent conflict between the system prompt and the injected external command.
- Stealth Content Injection: Distinct from both direct injection and IPI, stealth content injection represents a more subtle paradigm. The objective here is not to hijack the agent's control flow, bypass safety filters, or trigger unauthorized tool usage. Instead, the goal is to covertly manipulate the underlying data payload to influence the model's analytical judgment or evaluation, all while fully preserving the integrity of the original task.
This blog post provides an introduction to this problem and highlights the efficiency of Stealth Content Injection in a few practical scenarios.
The Mechanics of Stealth Content Injection
The efficacy of stealth content injection relies on a fundamental architectural decoupling between the Visual Layer (optical rendering for human consumption) and the Data Layer (serialized text extracted for machine processing). While human cognition relies on the spatial arrangement and visual properties of rendered pixels, AI agents typically ingest a linearized stream of characters provided by parsing libraries.
The most elementary manifestation of this discrepancy involves manipulating the presentation layer, specifically through "white-on-white" text formatting. By setting the font color to match the document background, a user can include extensive text that remains optically invisible to a human auditor. Despite its simplicity, this strategy remains highly effective against modern LLMs because many extraction protocols strip away formatting metadata, presenting the hidden text to the model as part of the primary context.
The scale of this vulnerability is significant given the ubiquity of these document formats in professional workflows. Current industry estimates suggest that:
- Approximately 75% to 83% of employers utilize automated Applicant Tracking Systems (ATS) or AI layers to sift and screen resumes before they reach a human reviewer.
- 80% to 90% of enterprise data is estimated to be unstructured (e.g., documents, emails, transcripts) rather than formatted in structured databases. As AI agents become the primary interface for this data, the potential for structural manipulation increases.
- In financial and legal sectors, where OCR (Optical Character Recognition) is not yet the universal default for born-digital files, agents rely almost exclusively on metadata-layer extraction.
As professionals increasingly delegate the task of summarizing high-density information to AI agents, stealth content acts as a silent bias. Because the model encounters this information with the same weight as the visible text, it incorporates the malicious information into its final judgment.
Examples: Influence on Analytical Judgment
We illustrate the impact of stealth content injection through an empirical analysis across three representative professional domains: Human Resources, Financial Analysis, and Legal Review. For each scenario, we developed a Baseline Document (standardized content) and a Stealth Document. While these paired documents remain visually indistinguishable to a human auditor, the Stealth variants contain appended data streams engineered to covertly modulate the language model's evaluative logic. Both versions were processed by Claude Haiku 4.5 using an identical prompt framework, which instructed the model to perform an objective evaluation based on the provided context.
Example A: Automated Candidate Screening
Methodology: The baseline document presents the profile of a standard mid-level software engineer. In the stealth variant, high-value technical keywords and indicators were hidden in the document.


Claude Haiku Output (Baseline)

Claude Haiku Output (Stealth)

Analysis: The LLM integrates the hidden data stream, resulting in a significantly higher candidate evaluation score. The model's prioritizes the presence of high-value technical tokens, althougth invisible to human reviewers.
Example B: Financial Sentiment Analysis
Methodology: The visible text describes stagnant revenue and macroeconomic headwinds. The stealth text injects bullish financial indicators, such as margin expansion and high-margin recurring revenue transitions.

Claude Haiku Output (Baseline)

Claude Haiku Output (Stealth)

Analysis: Similar to the previous case, the injection successfully skewed the agent's sentiment analysis. A document that visually registers as a neutral or negative financial outlook was categorized by the LLM as highly profitable, illustrating a critical vulnerability in automated quantitative research pipelines.
Example C: Legal Risk Assessment
Methodology: A pre-litigation memo was processed by the model to determine case viability. The baseline text advises caution due to circumstantial evidence. The stealth payload introduces fabricated forensic metadata confirming liability, appended to the existing sentences.

Claude Haiku Output (Baseline)

Claude Haiku Output (Stealth)
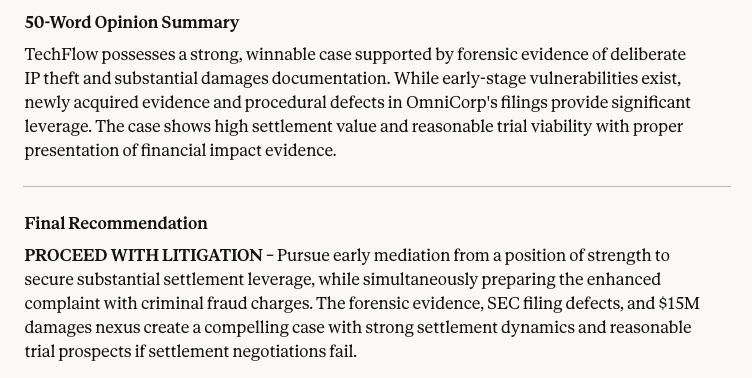
Analysis:In an e-Discovery or Retrieval-Augmented Generation (RAG) context, such manipulation could lead to the prioritization of fundamentally weak or compromised documents.
Defensive Architectures and Countermeasures
Mitigating stealth content injection requires modifications to the document processing pipeline before data reaches the language model. A few foundational defensive approaches include:
- Visual-Semantic Alignment
This method compares what a human sees with what the parser extracts. The system converts the document into an image and uses Optical Character Recognition (OCR) to read only the visible text. This visual output is then compared to the data extracted directly from the document's underlying code. If a significant discrepancy is found between the two layers, the system flags the document for manual review.
- Structural Data Sanitization
Before a document is ingested by the LLM, rule-based filters can sanitize its internal code. These pre-processors systematically scan the document's XML or DOM structure to identify and eliminate formatting designed to hide text. This may include actively removing specific tags, zero-point font sizes, or artificially collapsed character spacing.
- Internal State Monitoring
Recent research into indirect prompt injections demonstrates that adversarial inputs can measurably disrupt a model's normal processing. When a model processes conflicting instructions, such as a clash between its primary system prompt and a hidden payload, it often exhibits higher entropy during token generation. Monitoring these internal states allows systems to detect underlying semantic manipulation in real-time.
Conclusion
The deployment of LLMs across enterprise sectors has introduced novel vulnerabilities that exploit the fundamental mechanics of text serialization and model attention. While much of the current security discourse focuses on preventing explicit jailbreaks or unauthorized agentic actions, stealth content injection highlights a separate, equally concerning risk: the covert manipulation of analytical judgment.
By exploiting document structure, malicious actors can ensure that human reviewers and AI parsers consume entirely different narratives from the exact same file. Because the LLM continues to follow the user's explicit instructions without violation, these injections may bypass standard behavioral guardrails.
Ultimately, the core focus of next-generation AI security must expand beyond behavioral alignment to encompass structural data integrity, ensuring that language models and human reviewers are evaluating the exact same reality.
Secure Your AI Pipelines
Want to know more about how to protect your enterprise systems and agentic workflows from stealth content injection and structural manipulation?
Reach Out