Case Study: Engineering a Financial Data Factory
Customer need: A solution for a common bottleneck where analytical and quant teams was spend 80% of their time on engineering tasks such as cleaning, validating, and ingesting data rather than modeling. In the high frequency world of quantitative finance, this latency costs a competitive edge.
The Solution: Sabr Research architected a "Zero Touch" data factory. The goal was to build a serverless, scalable infrastructure that could orchestrate ingestion from diverse sources, enforce rigorous quality checks, and deliver clean tensors directly to machine learning pipelines without human intervention.
Scalability & Robustness from Day 1
For this project, scalability was a non negotiable requirement. The firm needed to ingest terabytes of market data daily without manual provisioning. We designed a cloud native architecture prioritizing "Day 1 Scalability." By leveraging Infrastructure as Code (IaC), we ensured that whether the system was integrating a new alternative data source or adding a new validation module, it would expand effortlessly.
To avoid long term technical debt, we implemented the entire stack using the AWS Cloud Development Kit (CDK). This allowed the engineering team to manage their infrastructure using familiar TypeScript logic rather than static configuration files. Below is an example of the modular stack structure delivered:
import * as cdk from 'aws-cdk-lib';
import * as lambda from 'aws-cdk-lib/aws-lambda';
export class DataPipelineStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
# ...
}
}To maximize maintainability, we architected the system using reusable patterns. For instance, independent parallel ingestion was required for EOD prices and news sentiment streams. We abstracted the creation of these ingestion nodes into modular helper functions:
const makeLambda = (
logicalId: string,
name: string,
cmd: string[],
timeout: Duration,
memorySize: number,
envVars: { [key: string]: string }
) => {
return new lambda.DockerImageFunction(this, logicalId, {
functionName: name,
code: lambda.DockerImageCode.fromImageAsset('../', {
cmd: cmd,
}),
timeout: timeout,
memorySize: memorySize,
environment: {
BUCKET_NAME: ...envVars,
},
});
};This approach allowed the team to "chain" logical steps into a cohesive pipeline without managing server states.
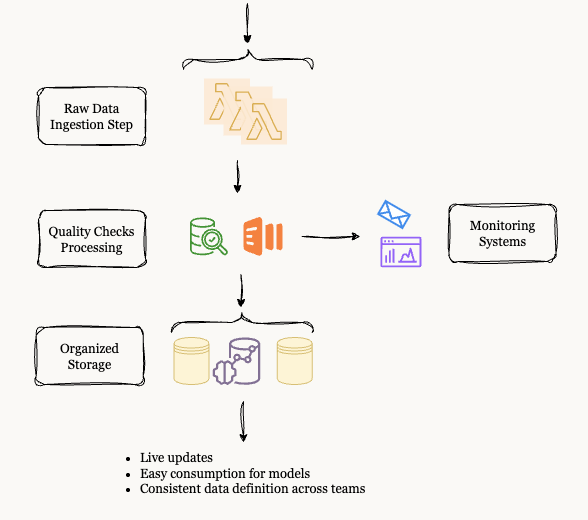
Figure 1: The architecture of the delivered Data Factory.
We orchestrated these chains using AWS Step Functions to ensure fault tolerance. If a data vendor's API failed, the system would automatically retry or alert, rather than crashing silently. Here is the orchestration logic implemented:
const parallelIngestion = new stepfunctions.Parallel(this, 'ParallelIngestion')
.branch(dataIngestionTask1)
.branch(dataIngestionTask2);
const aggregationStep = new stepfunctions.Pass(this, 'AggregateResults')
.next(new tasks.LambdaInvoke(this, 'DataAggregationTask'));
const dataProcessingFlow = aggregationStep
.next(qualityCheckTask)
.next(new stepfunctions.Choice(this, 'CheckQuality')
.when(stepfunctions.Condition.stringEquals('$.Payload.quality', 'good'), notifySuccessTask)
.otherwise(notifyFailureTask));
const definition = parallelIngestion
.next(dataProcessingFlow);
const stateMachine = new stepfunctions.StateMachine(this, 'DataPipelineStateMachine', {
definition,
timeout: Duration.minutes(timeout),
});This logic provided rapid deployment capabilities and consistent environments, reducing operational risk in trading operations.
Enforcing Data Integrity
The primary pain point was "garbage in, garbage out." To solve this, Sabr Research implemented a rigid quality assurance layer directly into the pipeline. We established four key pillars of integrity for the system:
Automated Schema Validation
Strict, standardized tests for every feature collected, ensuring only data conforming to the defined schema moves downstream.
Anomaly Detection Alarms
Real time monitoring systems that flag statistical anomalies immediately, preventing bad data from corrupting the model store.
Sandboxed Development
A multi stage environment strategy allowing researchers to test new features safely without risking the production trading environment.
Unified Feature Store
A centralized feature store that enforces point in time correctness, critical for avoiding forward looking bias in backtests.
These measures ensured that the quant team could trust their data implicitly, knowing that consistency was enforced by code, not manual review.
Case Study Outcome: Unleashing Science
The delivered framework successfully automated 90% of the data preparation work. By decoupling data engineering from data science, the Sabr Research solution allowed the team to focus purely on building and refining alpha models. The complexities of missing values, format inconsistencies, and aggregation are now handled intelligently by the "Data Factory," ensuring that the models are always powered by the highest quality inputs.