SR-AppellateLaw
A Specialized SLM
The Computational Cost of Generalization
Modern Large Language Models (LLMs) have demonstrated emergent reasoning capabilities across diverse domains, primarily as a function of massive parameter scaling. However, these capabilities introduce significant operational overhead in both capital expenditure and inference latency. Frontier models frequently require high-density GPU clusters for inference, activating hundreds of billions of parameters to process even localized, domain-specific queries.
From a resource allocation perspective, deploying such vast computational resources is often scientifically and commercially unjustified. When a model with a trillion-parameter general knowledge base is utilized for narrow, rule-bound tasks, the result is a significant misallocation of compute. Furthermore, despite high performance on mathematical and academic benchmarks, these models still struggle to reach human-level precision on specialized professional tasks. According to the PRBench (Professional Reasoning Benchmark) study, leading frontier models often plateau at scores as low as 37% on complex legal reasoning subsets, falling short of the reliability required for high-stakes professional adoption.
For domain-specific applications, this reliance on broad generalization results in measurable economic inefficiency and a persistent performance gap. In this context, utilizing a multi-modal, general-purpose frontier model for narrow, specific tasks represents an inefficient allocation of compute.
Specialization and its Benefits
Recent research suggests a shift toward smaller, high-density models is particularly relevant for the development of Agentic AI. These models allow for more scalable and intelligent resource allocation within autonomous workflows. Small Language Models (SLMs), typically within the 7B to 12B parameter range, offer significantly lower latency and reduced inference costs compared to their frontier counterparts. Beyond efficiency, the reduced memory footprint of SLMs enables deployment on local hardware, allowing enterprises to maintain full data sovereignty and process sensitive information without reliance on third-party cloud infrastructure.
The central thesis of SLM specialization is that a model with fewer parameters can match or exceed the performance of a larger generalist model if its weights are optimized for specific distributions through Supervised Fine-Tuning (SFT). While various methodologies exist, we highlight two important paradigms:
- Outcome-Based Fine-Tuning: This method prioritizes the statistical alignment of inputs to correct outputs. For example, in the financial domain, a model might be trained on a massive Q&A dataset to map quarterly earnings transcripts directly to standardized GAAP metric extractions. The primary goal is achieving the correct terminal result, which may come at the expense of transparent reasoning, or reward hacking.
- Process-Based Fine-Tuning (PRM): This approach focuses on teaching the model to reach the correct output by following an explicit, step-by-step logical methodology. It emphasizes the "Chain of Thought" (CoT), ensuring each intermediate inference step is technically sound and verifiable.
By distilling the reasoning requirements of a specific field into an SLM, organizations can achieve frontier-level precision while maintaining local control and reducing per-token expenditure by several orders of magnitude. In this context, the quality and structure of the data used for SFT are the primary determinants of performance gains. Currently, the industry relies heavily on manually curated datasets; however, these are notoriously cost-prohibitive and difficult to scale due to the requirement for high-level human expert labor to annotate complex logical paths.
SFT Through Proprietary Argumentation Graphs
The empirical focus of this study centers on the adjudication process within State Appellate Courts (retrieved from here). Unlike trial courts, which are primarily concerned with factual discovery and witness testimony, appellate courts serve a strictly corrective function. Their role is to review the record of a lower court to determine if legal errors were committed that prejudiced the outcome. Consequently, the Supervised Fine-Tuning (SFT) task defined here is the prediction of the appellate judicial action based on the case record. The possible outcomes are categorized into three distinct classes: Affirm (upholding the lower court's decision), Reverse (overturning the decision due to legal error), or Mixed (partially affirming while vacating or reversing other elements of the ruling).
The appellate court determines the lower court reached the correct result without reversible error.
The appellate court identifies a legal or procedural error that necessitates overturning the ruling.
The court upholds some parts of the ruling while reversing or vacating others.
This task is specifically chosen for its difficulty. Appellate review does not focus on factual discovery but on the abstract application of law to established facts, requiring higher-order logical deduction.
While high-quality summaries of court judgments are readily available for SFT, the efficacy of the fine-tuning process is heavily dependent on the structural quality of the training inputs. A "naive" approach to SFT involves utilizing the full, raw text of a case rationale as the target output. However, legal prose is often characterized by dense rhetorical elements, jurisdictional boilerplate, and peripheral procedural discussions that do not contribute to the core logical derivation. This "noise" complicates the gradient descent process by forcing the model to allocate parameters to non-dispositive vocabulary and stylistic mimicry rather than causal reasoning.
To mitigate this, we have developed a proprietary framework to transform raw legal rationale into Reasoning-Aware Argumentation Graphs. This process essentially distills the text into a structured topology of facts, logical rules, preferences, and conclusions. By fine-tuning the model on these structured logical chains rather than raw narrative text, we enhance the model’s internal attention mechanism, improving its ability to identify relevant sequence of logical steps beyond pure semantics.
Empirical Analysis
To evaluate the efficacy of structural specialization, we conducted a comparative analysis using Llama 3.1 8B Instruct as the base architecture for fine-tuning. We compared three distinct iterations of this model: the baseline version, a variant fine-tuned on Naive Raw Text, and our proprietary version, which utilizes Reasoning-Aware Argumentation Graphs.
For the comparative baseline, we selected Claude 4.5 Sonnet and DeepSeek R1. These models represent the current state-of-the-art in frontier general-purpose reasoning. While these high-parameter models exhibit significant latent capabilities, the objective of this study was to measure the "intelligence-per-dollar" efficiency against a specialized SLM.
Operational Efficiency Metrics
The operational disparity between the architectures is significant. From an economic standpoint, Claude 4.5 Sonnet is 27 times more expensive to operate on a blended token basis than the specialized 8B model. Regarding throughput, the SR-AppellateLaw model achieves an inference speed of 2,200 tokens per second. In contrast, DeepSeek R1 is approximately 63 times slower, while Claude 4.5 Sonnet is 20 times slower.
The table below details the performance of the various models across our test set. Notably, the Llama 8B model fine-tuned on structured logic graphs (SR-AppellateLaw) outperformed frontier-class models like Claude 4.5 Sonnet in outcome prediction accuracy and balanced F1 score, validating the premise that domain-specific data structure can outweigh raw parameter scaling.
| Model Configuration | Accuracy | F1 (Macro) | Instr. Following |
|---|---|---|---|
| Llama 8B Instruct | 40.71% | 20.76% | 94.69% |
| Llama 8B Instruct Raw Text SFT | 45.13% | 25.74% | 90.27% |
| SR-AppellateLaw | 65.49% | 42.94% | 100% |
| Claude 4.5 Sonnet (Zero-Shot) | 61.06% | 34.67% | 97.35% |
| DeepSeek R1 (Zero-Shot) | 67.26% | 49.72% | 100% |
In addition to absolute accuracy, we monitored Instruction Following Reliability across all test samples. Our empirical findings indicate that only the specialized SR-AppellateLaw model and DeepSeek R1 achieved a 100% adherence rate in maintaining the required output schema (constrained to Affirm, Reverse, or Mixed classifications accompanied by structured rationale).
Furthermore, the data suggests a qualitative ceiling for models trained via Naive Raw Text SFT. While this approach yielded marginal gains in performance, an analysis of the model's rationale reveals that the improvement is primarily driven by the acquisition of legal nomenclature and style. In contrast to our graph-based approach, the raw text model frequently fails to execute the intermediate logical steps required for consistent reasoning, relying instead on jargon-heavy guesses.
Multi-Dimensional Qualitative Analysis
Beyond classication performance, understanding the structural quality of an AI's legal reasoning is critical for enterprise deployment. We utilized a LLM-as-a-Judge pipeline (Amazon Nova Pro) to evaluate the generated rationales across four specific appellate dimensions:
- Logical Alignment
Measures the alignment between the model's derived logical path and the ground truth reasoning. High scores indicate the model successfully identified the core dispositive issues and pivotal arguments rather than focusing on peripheral or irrelevant legal theories.
- Factual Grounding
Evaluates the model's strict adherence to the provided case facts. This metric specifically penalizes the hallucination of facts, parties, or events, ensuring that the rationale is anchored in the explicit inputs of the lower court ruling and factual summary.
- Legal Soundness
Assesses the internal consistency and logical validity of the rule application. A high score confirms that the model logically connected the facts to the conclusion using valid legal mechanics, without generating contradictory statements or applying hallucinated legal standards.
- Reasoning Efficiency
Quantifies the conciseness and directness of the generated rationale. This metric penalizes conversational filler, redundant procedural boilerplate, and rhetorical artifacts, all of which increase token output costs and dilute the clarity of the legal analysis.
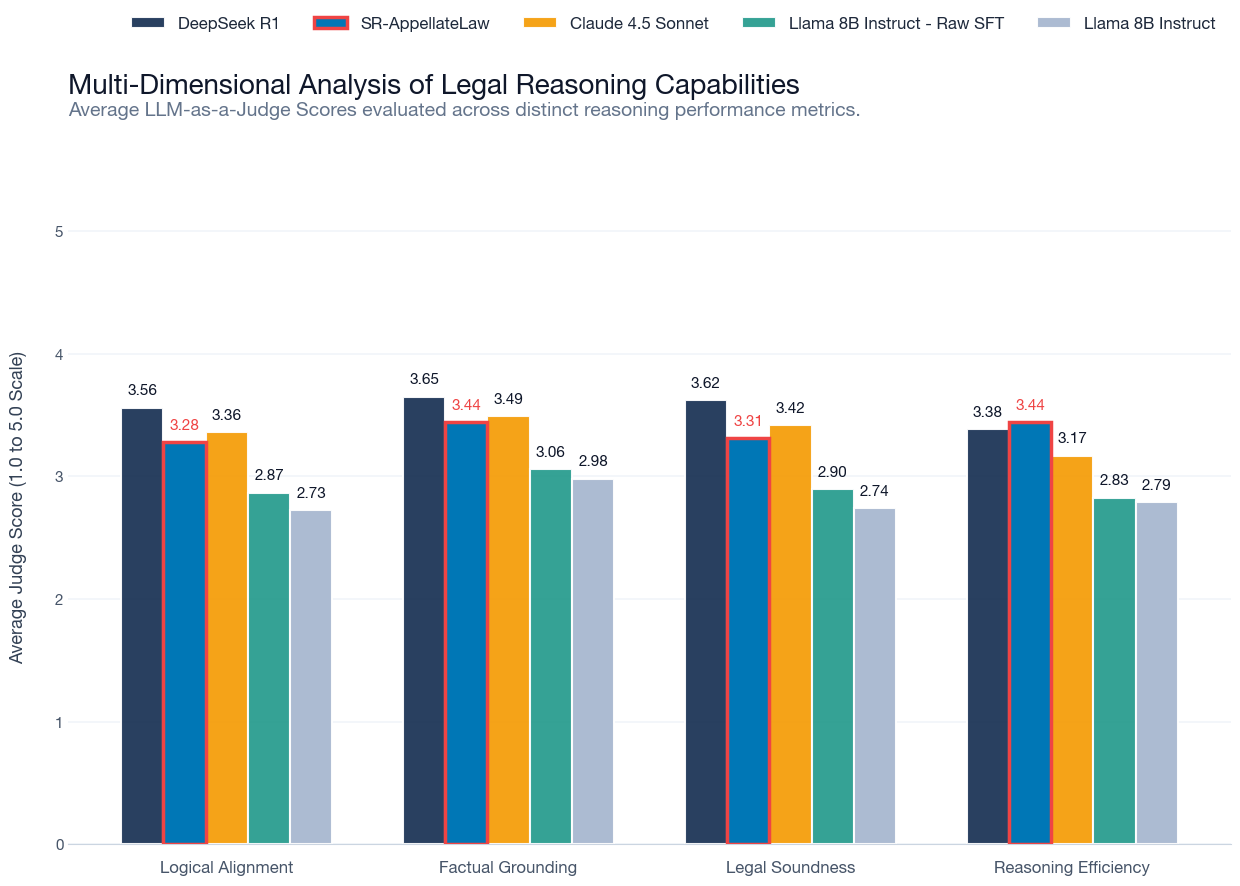
Figure 1.1: Average judge scores (1.0 to 5.0 scale) evaluated across distinct reasoning performance metrics. The specialized SR-AppellateLaw model demonstrates highly competitive logic capabilities, notably outperforming frontier models in Reasoning Efficiency.
As illustrated in Figure 1.1, SR-AppellateLaw is able to reach or exceed the reasoning quality frontier models like DeepSeek R1 and Claude 4.5 Sonnet for a fraction of the cost.
The Verbosity Penalty in Frontier Models: General-purpose models are intrinsically aligned to be conversational and exhaustively helpful. In an our context, this manifests as "procedural fluff" or legal word salad, unnecessary recitations of standard review protocols that dilute the core dispositive argument. Claude 4.5 Sonnet (3.17) and DeepSeek R1 (3.38) both incur penalties for this verbosity.
Conversely, the SR-AppellateLaw model achieves the highest Reasoning Efficiency score (3.44). Fine-tuning on proprietary argumentation graphs successfully conditioned the 8B parameter model to bypass rhetorical boilerplate, isolating and articulating only the relevant logical paths. In an enterprise environment, this facilitates a more rigorous human review process by prioritizing structural transparency over the style and eloquence characteristic of general-purpose frontier models.
This finding confirms a core hypothesis of specialized SLM architecture. While raw text fine-tuning demonstrates a measurable increase in classification performance compared to the base model, its qualitative reasoning scores are only marginally improving. This suggests that the accuracy gains in raw SFT are predominantly driven by surface-level pattern matching and nomenclature acquisition rather than a structural improvement in reasoning capabilities.
In contrast, our proprietary graph-based fine-tuning fundamentally alters the model's analytical conciseness. For enterprise pipelines, this translates directly to lower output token costs and a significant reduction in latent operating expenses. More importantly, it facilitates a more rigorous human-in-the-loop review process by prioritizing structural transparency over the eloquent noise that often masks logical flaws in frontier models.
Conclusion
The empirical evidence confirms that for specialized appellate reasoning, a small language model optimized via proprietary logic graphs delivers a significant increase in performance, close to matching that of frontier models for a fraction of the cost.
These results indicate that structural representation in training data is a primary lever for model efficiency. For high-stakes professional domains, specialization through structured logic allows organizations to deploy frontier-level intelligence while maintaining significant computational and economic advantages.
References
- Akyürek, A. et al. (2025). PRBench: Large-Scale Expert Rubrics for Evaluating High-Stakes Professional Reasoning.arXiv preprint arXiv:2511.11562.
- Belcak, P. et al. (2025). Small Language Models are the Future of Agentic AI.arXiv preprint arXiv:2506.02153
- Hu, E. J. et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models.https://arxiv.org/pdf/2106.09685
- Zhou, C. et al. (2023). LIMA: Less Is More for Alignment.arXiv preprint arXiv:2305.11206.
- Meta AI Research (2024). Llama 8B Model Card and Technical Reports.